MQ 介绍
MQ(Message Queue)消息队列,是基础数据结构中“先进先出”的一种数据机构。指把要传输的数据(消息)放在队列中,用队列机制来实现消息传递——生产者产生消息并把消息放入队列,然后由消费者去处理。消费者可以到指定队列拉取消息,或者订阅相应的队列,由MQ服务端给其推送消息。
MQ的作用
消息队列中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构。
解耦:一个业务需要多个模块共同实现,或者一条消息有多个系统需要对应处理,只需要主业务完成以后,发送一条MQ,其余模块消费MQ消息,即可实现业务,降低模块之间的耦合。
异步:主业务执行结束后从属业务通过MQ,异步执行,减低业务的响应时间,提高用户体验。
削峰:高并发下,业务异步处理,提供高峰期业务处理能力,避免系统瘫痪。
MQ的缺点
1、系统可用性降低。依赖服务也多,服务越容易挂掉。需要考虑MQ瘫痪的情况
2、系统复杂性提高。需要考虑消息丢失、消息重复消费、消息传递的顺序性
3、业务一致性。主业务和从属业务一致性的处理
主要的MQ产品
主要的MQ产品包括:RabbitMQ、ActiveMQ、RocketMQ、ZeroMQ、Kafka、IBM WebSphere 等。
MQ理论介绍
一、为什么需要消息队列(MQ)
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。大量的请求到达访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection错误,引发雪崩效应。我们使用消息队列,通过异步处理请求,从而缓解系统的压力。核心:异步处理、流量削峰、应用解耦
二、应用场景
异步处理,流量削峰,应用解耦,消息通讯四个场景
2.1、异步处理
场景1:用户注册后,需要发送注册邮件和注册短信。
- 串行方式:将注册信息写入
数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端
- 串行方式:将注册信息写入
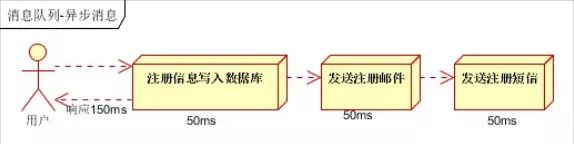
- 并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间
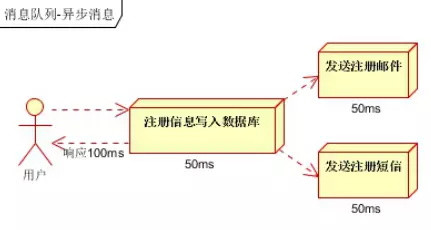
假设三个业务节点每个使用50毫秒钟,不考虑网络等其他开销,则串行方式的时间是150毫秒,并行的时间可能是100毫秒。 因为CPU在单位时间内处理的请求数是一定的,假设CPU在1秒内吞吐量是100次。则串行方式1秒内CPU可处理的请求量是7次(1000/150)。 并行方式处理的请求量是10次(1000/100)
小结:如以上案例描述,传统的方式系统的性能(并发量,吞吐量,响应时间)会有瓶颈。如何解决这个问题?
- 引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:
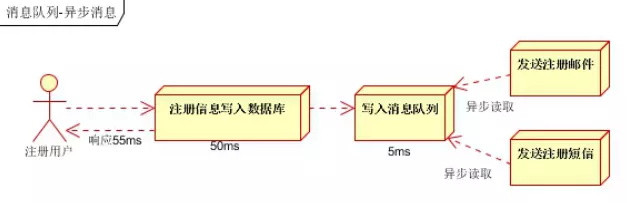
按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是50毫秒。注册邮件,发送短信写入消息队列后,直接返回, 因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是50毫秒。因此架构改变后,系统的吞吐量提高到每秒20 QPS。 比串行提高了3倍,比并行提高了2倍。
- 场景2:订单处理,前端应用将订单信息放到队列,后端应用从队列里依次获得消息处理,高峰时的大量订单可以积压在队列里慢慢处理掉。
2.2、流量削峰
流量削峰也是消息队列中的常用场景,一般在 秒杀或团抢活动 中使用广泛
应用场景:秒杀活动,一般会因为流量过大,导致流量报增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。
可以控制活动的人数
可以缓解短时间内高流量压垮应用
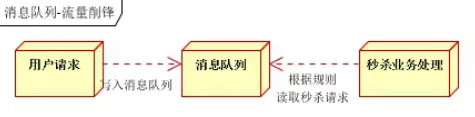
- 让消息不直接到达服务器,而是先让 「消息队列」 保存这些数据,然后让下面的服务器每一次都取各自能处理的请求数再去处理,这样当请求数超过服务器最大负载时,就不至于把服务器搞挂了。
- 秒杀业务根据消息队列中的请求信息,再做后续处理
2.3、应用解耦
- 场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用系统库存接口。
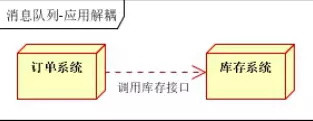
传统模式的缺点:
假如库存系统无法访问,则订单减库存将失败,从而导致订单失败
解决订单系统与库存系统耦合,如何解决?
引入消息队列后的方案:
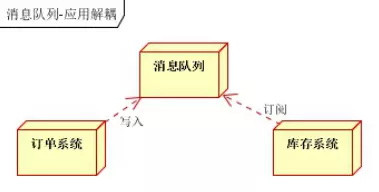
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功 库存系统:订阅下单的消息,采用pub/sub(发布/订阅)的方式,获取下单信息,库存系统根据下单信息,进行库存操作
- 假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入信息队列就不再关心其他后续操作了。实现订单系统与库存系统的应用解耦。
2.4、日志处理
日志处理是将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。架构简化如下

日志采集客户端,负载日志数据采集,定时写入Kafka队列
Kafka消息队列,负载日志数据的接收,储存和转发
日志处理应用:订阅并消费Kafka队列中的日志数据
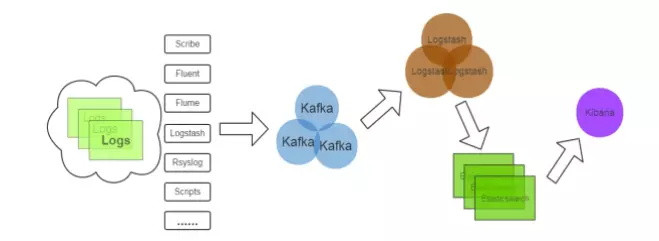
- (1) Kafka:接收用户日志的消息队列
- (2) Logstash:做日志解析,统一成JSON 输出给Elasticsearch
- (3)Kibana:基于Elasticsearch 的数据可视化组件,超强的数据可视化能力是众多公司选择Elkstack的重要原因
2.5、消息通讯
消息通讯是指,消息队列一般都内置了高效的通信机制就,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
- 点对点通讯:
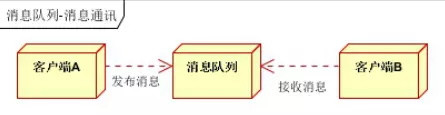
客户端A和客户端B使用同一队列,进行消息通讯。
- 聊天室通讯:
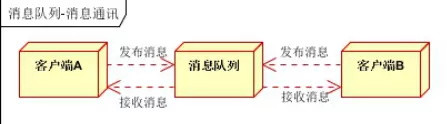
客户端A,客户端B,客户端N订阅同一主题,进行消息发布和接收。实现类似聊天室效果。以上实际是消息队列的两种消息模式,点对点或发布订阅模式。
3、衡量指标
我们从服务性能、数据存储、集群结构三个方面去对比,选择适合自己项目的消息中间件
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级 | 万级 | 十万级 | 十万级 |
| topic 数量对吞吐量的影响 | - | - | topic 可以达到几百,几千个的级别,吞吐量会有较小幅度的下降 | topic 从几十个到几百个的时候,吞吐量会大幅度下降 |
| 时效性 | 毫秒级 | 微妙级 | 毫秒级 | 毫秒级 |
| 可用性 | 高 | 高 | 非常高,分布式架构 | 非常高,分布式架构 |
| 消息可靠性 | 有较低的概率丢失数据 | - | 经过参数优化配置,可以做到 0 丢失 | 经过参数优化配置,消息可以做到 0 丢失 |
| 功能支持 | 完善 | 并发能力很强,性能极其好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
| 优劣势总结 | 非常成熟,功能强大;偶尔会有较低概率丢失消息;社区不活跃了 | 性能极其好,延时很低;功能完善;提供管理界面;社区比较活跃;吞吐量较低;使用 erlang 开发源码阅读不方便; | 接口简单易用;吞吐量高;分布式扩展方便;社区还算活跃;经过双 11 的考验 | MQ 功能比较少;吞吐量高;分布式架构;可能存在消息重复消费问题;主要适用大数据实时计算以及日志收集; |
4、AvctiveMQ和RabbitMQ
4.1、ActiveMQ
特点:
早期主流的消息中间件,包括ZeroMQ,但是这几年使用的很少了,主要在长期维护的项目中使用。API丰富,本身很成熟但是在高并发、大数据
环境下的性能不够出色,主要试用于中小型项目,有较低的概率丢失数据,最主要是的,官方现在维护的频率一直在降低,好几个月才发布一个版本。
架构:
1、Master-Slave模式,通过Zookeeper实现节点切换和故障转移
2、NetWork模式,相当于多套Master-Slave模式,通过NetWork网关进行集成
4.2、RabbitMQ
RabbitMQ 是使用 Erlang 语言开发的开源消息队列系统。基于AMQP协议来实现的。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布与订阅)、可靠性、安全。
AMQP协议:更多的用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次场景。
好处在于可以支撑高并发、高吞吐、性能很高,同时有非常完善便捷的后台管理界面可以使用。另外,他还支持集群化、高可用部署架构、消息高可靠支持,功能较为完善。
http://www.virplus.com/thread-1303.htm
转载请注明:2020-5-10 于 VirPlus 发表


